

html 태그 정리 (이미지, 하이퍼링크, 문자 태그 등)

확률표본추출(확률표집) 방법 쉽게 이해하기
이번에는 도서관에서 목록 작업을 위해 사용하는 MARC의 구조에 대해 세밀히 들여다 보고자 한다. 물론 이 구조와 원리를 알고 있지 않더라도 MARC 작업하는데 지장은 없지만, 이를 알고 나면 상황에 따라 발생하는 일들에 대처하는 능력이 좋아질 것이라 생각한다.
본 자료에서는 ‘삼국지’라는 책을 예제로 삼아 하나의 구조를 면밀히 분석해 볼 것이다.
MARC 들어가기
![국립중앙도서관 [삼국지] 서지정보](https://www.gklibrarykor.com/wp-content/uploads/2023/09/국중-마크보기.jpeg)
국립중앙도서관 [삼국지] 서지정보
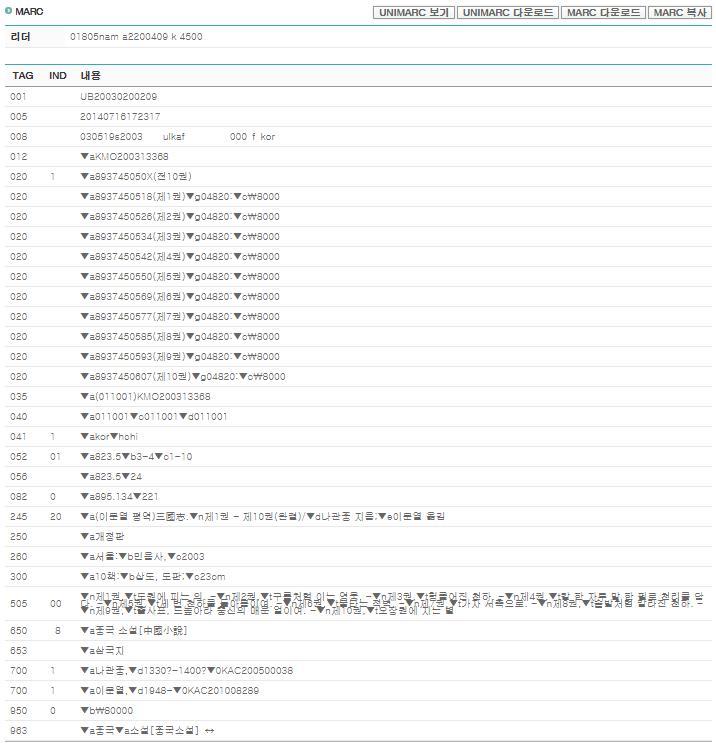
MARC 보기
위 이미지는 [MARC 보기]를 통해 본 삼국지에 대한 목록작업 결과이다. 문헌정보학 전공자나 도서관에 근무하는 사람이라면 익숙히 알고 있을 법한 화면이다.
이 화면에서는 태그를 중심으로 지시기호와 식별기호 등으로 구분한 서지정보를 확인할 수 있다.
이와 관련하여 목록작업을 위한 KORMARC 태그에 대한 내용은 아래의 자료를 참고하면 도움이 될 것이다.

이번 자료에서 다루고자 하는 내용은 ‘마크 보기’ 화면에서 한 단계 더 들어가 위와 같은 화면이 나오는 과정을 알아보려는 것이다.
해당 화면에서 MARC 파일을 다운로드 받을 수도 있는데, 이 파일을 받아 한글문서로 열어본 결과는 아래와 같다.

정신없어 보이는 글자들 (MARC 원본)
이 내용을 보면 느껴지는 바가 있을 것이다. 홈페이지에서 보였던 정리된 내용과는 달리 무척 복잡하고 정신없어 보인다. 순서도 앞서 태그별로 정리되었던 내용과는 달리 정신없이 숫자들만 쭉 나열된 뒤에 책에 대한 정보가 나온다.
즉, 앞서 태그 – 지시기호 – 필드 순으로 깔끔하게 나왔던 모습과 달리, 이전에는 보이지 않던 디렉터리가 포함돼 리더 – 디렉터리 – 필드 정보가 표시된 것이다.
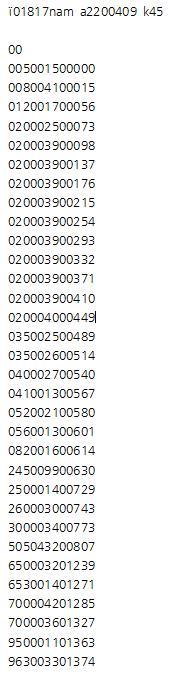
숫자 정리 결과
정신없이 나열되어 있던 숫자를 12자리씩 끊어 정리한 결과는 위와 같다. 이 숫자들의 앞 세 글자를 자세히 보면 알겠지만 MARC의 태그 번호를 의미한다.
참고로 캡처한 이미지 위쪽에 ’00’이 따로 떨어져 있는 것은 원래 맨 윗줄 리더 뒤에 4500이 되어야 한다.
그럼 왜 숫자를 12자리씩 끊었는지, 이전에는 알 수 없었던 리더와 디렉터리는 무엇인지 아래의 이미지를 통해 확인해 볼 것이다.
MARC 구조와 원리
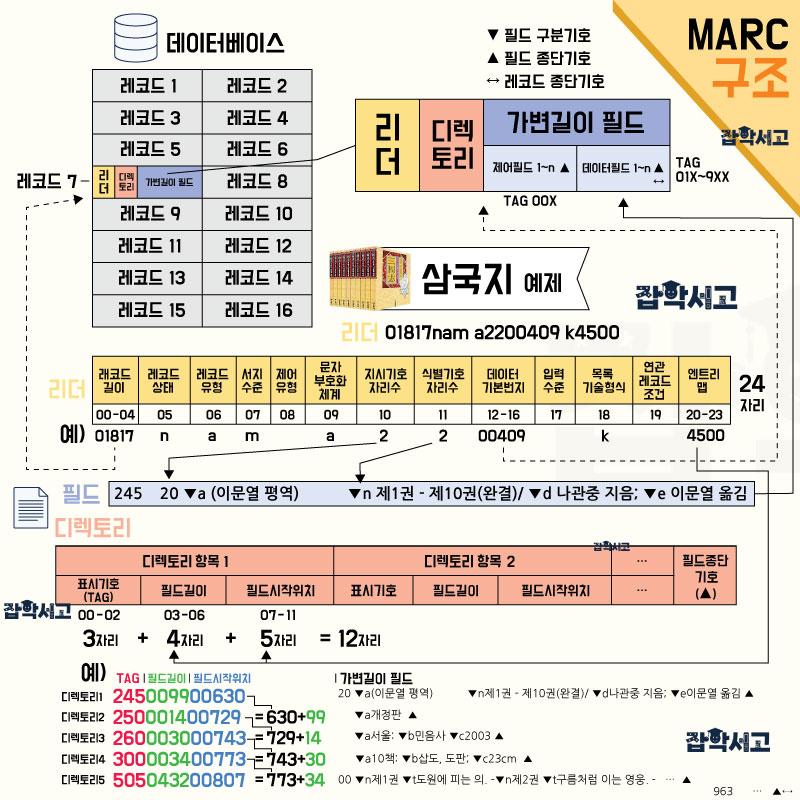
MARC의 구조 개념도
앞의 복잡한 정보들을 한눈에 보기 쉽도록 이미지 한 장으로 모아 정리해 보았다. 정보가 많아 복잡해 보일 수 있지만 위에서부터 하나씩 잘 살펴보면 앞서 보였던 복잡한 숫자와 내용들이 어떤 식으로 구성되었는지 알 수 있을 것이다.
가장 상위의 개념이라 할 수 있는 것은 모든 정보를 담고 있는 데이터베이스라 할 수 있으며, 그 안에는 각 책에 대한 정보를 담고 있는 레코드가 무수히 많이 담겨 있다.
(DB > 레코드 > 리더 > 디렉터리 > 필드)
이러한 레코드는 리더, 디렉터리, 가변길이필드로 구분되는데, 리더는 24자로 구성되어 해당 레코드에 대한 기본 정보 및 탐색을 위한 정보를 담고 있으며, 디렉터리는 MARC 작업 창의 줄(열) 단위인 각 필드에 대한 정보(TAG[3자], 길이[4자], 시작 위치[5자])를 담고 있다.
여기서 각 디렉터리는 12자로 구성되어 있으며 실제 MARC 데이터에서는 가변길이필드가 나오기 전까지 구분 없이 쭉 붙어 있다.

245 TAG의 지시기호

245 TAG의 식별기호
마지막 가변길이필드는 흔히 MARC 보기를 통해 보이는 지시기호, 식별기호(▼), 서지정보 등의 내용이 담겨있으며, 각 필드의 끝에는 필드 종단기호(▲)를 넣고 각 레코드의 끝에는 레코드 종단기호(↔)를 넣어준다.
이상으로 MARC의 구조와 원리에 대하여 알아보았다. 본 내용은 통합서지용KORMARC를 기준으로 작성하였으며, 이후 새로운 MARC가 나온다면 일부 바뀔 수는 있겠지만 큰 틀에서는 이와 비슷한 방식으로 갈 것으로 보인다.
확실히 익히고자 한다면 MARC 구조를 참고하여 직접 국립중앙도서관 홈페이지에서 MARC 데이터를 다운로드해 본 자료처럼 각 요소들을 분석하면 익숙해질 수 있을 것이다.





